Here, you will find spectrograms and audio clips to augment our paper.
Quantitative metrics can be helpful in generally assessing the capabilities of an audio processing technique, when the ground truth is known. However, given the subjective nature of instrumental audio, being able to audition the results is often more useful.
In our paper, we highlight analogous image tasks to each MIR task. To recap:
-
Source-separation becomes a denoising problem, reconstructing frequencies related to the signal and ignoring others.
-
Super-resolution is analogous to inpainting, where the blank half of a spectrogram is filled by considering the first half (the low frequencies) and prior knowledge.
-
Synthesis becomes a style transfer problem, where the model has extracted the overall harmonic ‘style’ of an instrument, and seeks to apply this to sine-waves serving as a harmonic blueprint
-
Pitchtracking can be thought of as semantic segmentation in the same way that a satellite image might be translated into a road map.
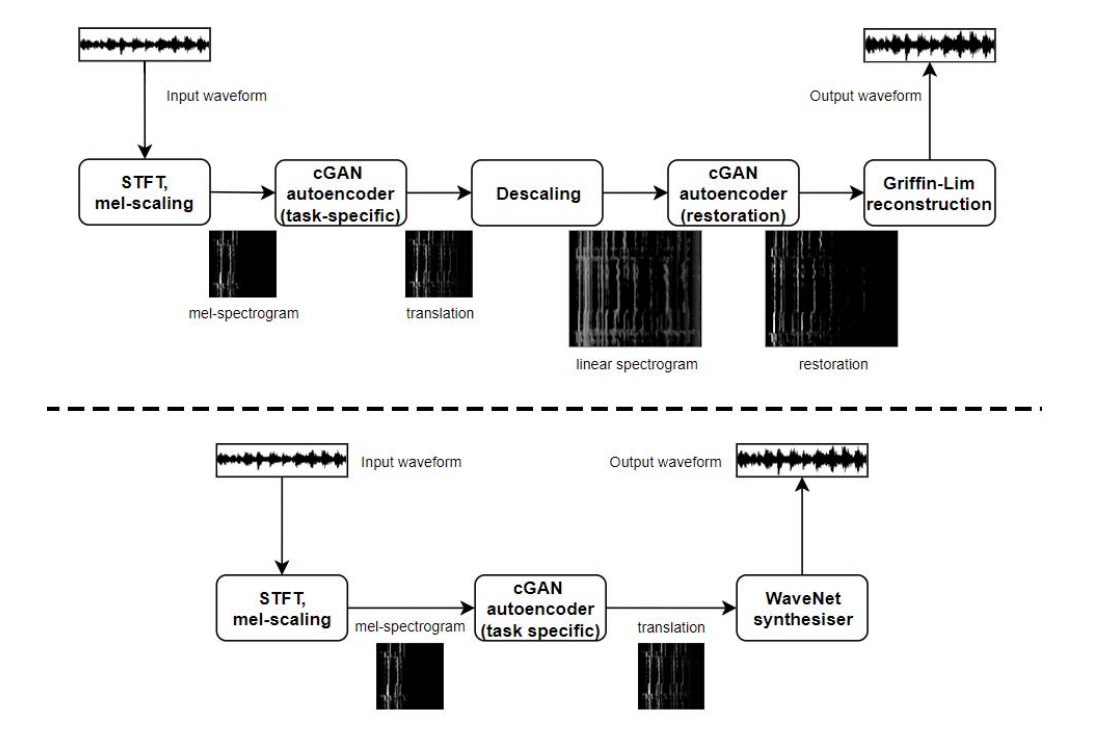
We introduce two pipelines to achieve this, shown below. The top details GAN-S, which uses a secondary cGAN stage to aid reconstruction, while the bottom details GAN-WN.
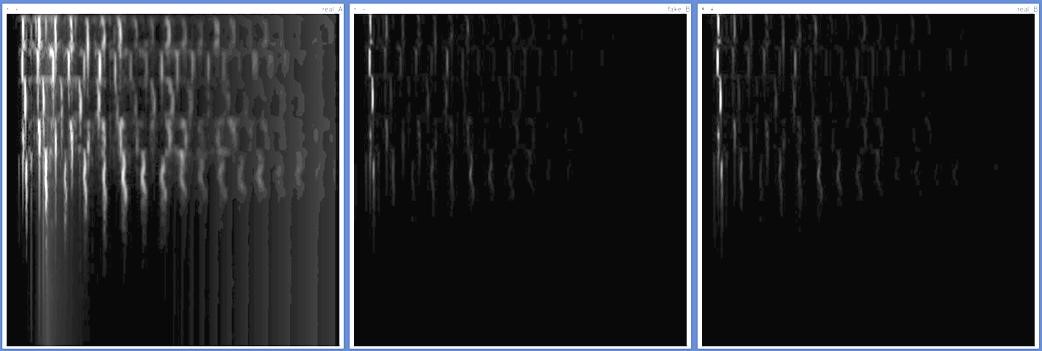
Below is an example linear spectrogram, restored using the secondary cGAN. From left to right: descaled spectrogram, restoration, ground truth.
Given the subjective nature of the first three tasks, we provide an audio demonstration of each below.
1. Source-separation as Denoising
We start with a recording of a piano and violin duet, playing a phrase from Bach.
Following the top pipeline from the above figure, our process looks for frequencies specific to the violin, and attempts to silence the piano.
Another example from the same piece.
Now, our CNN baseline has a go at isolating the violin.
The result from our method. It introduces a different sort of artefact, losing high-frequency fidelity primarily due to the lossy spectrogram reconstruction process. Yet, notice the piano source is much better attenuated.
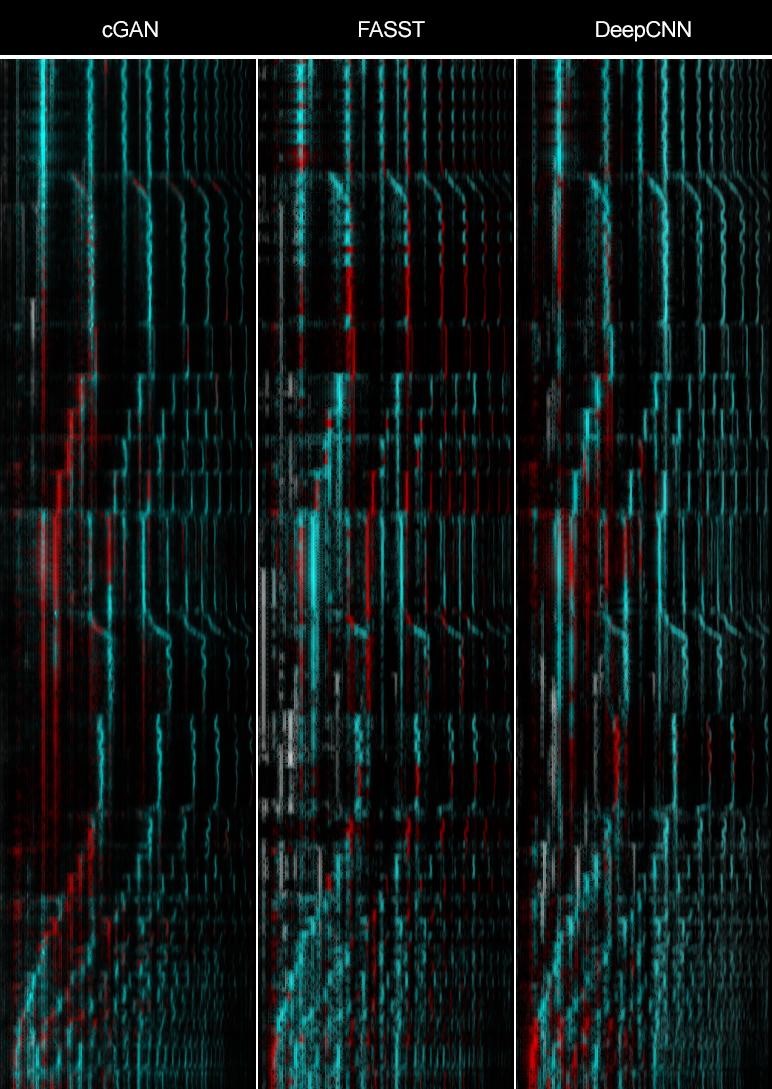
Below, we give a closer look at source-separation, with a ground-truth difference overlay. Alignments with ground truth are cyan. Areas where ground truth is missed are red. Interference (piano) is white. Observe cGAN’s precision in removing interference, sometimes at the cost of detail.
2. Super-resolution as Spectral Inpainting
We start with a violin phrase by Paganini, at a sample rate of 4kHz (ultra low-fidelity).
Here’s the result of our method.
This is the ground truth.
Another example. This time, from Chopin. Here is the lofi clip:
Here is the baseline performance (linear interpolation):
Here is the result of our cGAN process.
Ground truth.
Alternatively, we can use a Wavenet to reconstruct the raw audio directly from the Mel-spectrogram (see the lower pipeline in the figure from before). This kind of modelling proved to be highly resource intensive, with training taking over a fortnight to see convergence on our NVIDIA GTX1080ti. Despite lacking the memory necessary to train a sufficiently complex model, the concept is there.
We can further improve the output of our unstable Wavenet. Instead of conditioning Wavenet on the spectrogram alone, we also feed in the timesteps of the original, lofi audio. At every step, we now take the average of both original audio and Wavenet’s prediction (weighted towards the former). This can be thought of as a sort of teacher-forcing generation. As usual, that timestep becomes part of the series, and in turn influences future predictions. Here, we apply this to our Chopin clip.
3. Synthesis as Style Transfer Onto Harmonics
Here is the melody from the folk song, ‘Scarborough Fair’, as played by a sinewave generator. These sinewaves include the fundamental as well as the first few harmonics, in order to provide structure for cGAN to translate.
Here is the same harmonic track, with the violin ‘style’ applied:
Finally, we leave the reader with the first 7 notes of the chorus of Rick Astley’s “Never Gonna Give You Up”, as played by a sinewave generator.
Here is the result of our method, applying violin stylisation :)